Week 09/40: CatAtlas Insight Engine
Shipping a tiny AI project every week to rebuild hands-on AI engineering skills.
This week: RAG-lite retrieval + structured “GenAI” outputs + caching (without calling an LLM yet)
0) Tech stack (current setup)
Frontend: React + TypeScript (Vite)
Backend: FastAPI (Python)
Storage: SQLite (raw SQL)
AI approach: deterministic heuristics + “GenAI-style” structured output (LLM-ready contract)
Dev env: GitHub Codespaces + public ports (5173 frontend / 8000 backend)
Testing: pytest + FastAPI TestClient
1) Why this week? (Context & Intent)
This week, I wanted to explore how to build a real GenAI feature beyond “just call an LLM”.
CatAtlas already had sightings, matching, and basic profiles — but it was missing a repeatable AI pipeline that feels product-grade and debuggable.
I deliberately scoped this to a single thin vertical slice to practice:
shipping over perfection
explainable logic before models
clean API boundaries (so an LLM can be swapped in later)
2) What I shipped (Concrete & Verifiable)
What’s live:
Users can request AI-style insights for a cat (profile / care / risk / updates)
The system retrieves relevant sightings for that cat (RAG-lite)
Output includes structured fields and citations (which sightings were used)
🔗 Demo / Repo:
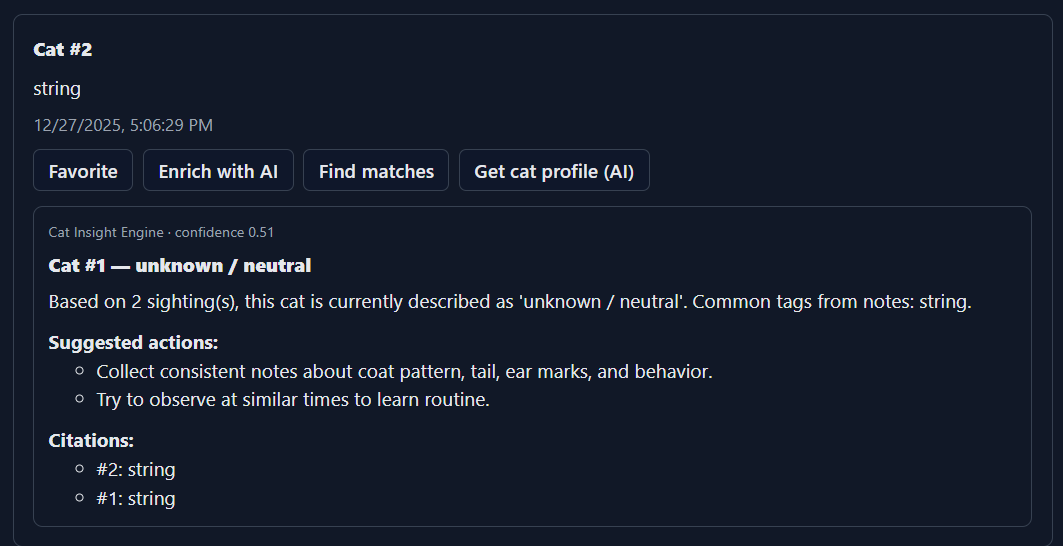
3) The One Feature Rule (Scope Discipline)
This week’s one feature:
A Cat Insight Engine endpoint that produces structured insights from retrieved sightings.
What I intentionally did NOT build:
No real LLM integration
No embeddings or vector database
No authentication
No UI polish beyond readability
No photo understanding
4) Architecture (Tiny but Real)
Architecture (v0):
Frontend
Calls
POST /cats/{cat_id}/insightsRenders the returned JSON directly
Backend (FastAPI)
Retrieve recent sightings for the cat
Build a context bundle
Generate structured insights (stub generator)
Cache results in SQLite using a context hash
Design rule:
👉 Models can be swapped later without breaking contracts.
5) The “AI” Part
5.1 Baseline logic (v0)
Before touching any model, I implemented:
Retrieval (RAG-lite):
Fetch the cat’s most recent (and later: most relevant) sightingsContext hashing:
If the sightings change, the hash changes → cache invalidatesStructured output:
A JSON response containing:headline, summary, confidence
flags (risk signals)
suggested actions
citations (sighting excerpts)
Every “AI” output is transparent and traceable to source data.
5.2 Why this matters
This gives me:
Debuggability — I can see why the system said something
Testability — schemas can be asserted in tests
A baseline — future LLM or embedding improvements can be compared objectively
This is GenAI engineering, not prompt roulette.
6) What Broke (and How I Fixed It)
Problems I hit:
React Invalid hook call
→ I accidentally placed auseStateoutside the componentTypeScript contract mismatch
→ frontend expected fields that didn’t exist yet
Fix:
Moved hooks back inside
App()(hooks must be top-level in a component)Updated TypeScript types to exactly match the backend response schema
7) What I Learned (Engineering Takeaways)
GenAI features start with contracts and pipelines, not models
Retrieval + citations are the backbone of trust
Caching via context hashes makes AI outputs usable in real products
Shipping small surfaces integration bugs early (UI ↔ API ↔ DB)
8) What’s Next (v1, but not next week)
Obvious next steps (not doing yet):
Replace heuristic generator with a real LLM call
Swap retrieval to embeddings (vector search)
Add user feedback (“helpful / not helpful”)
Next week will stay small and focused again.
9) Follow along
Your task: Build the Insight Engine in one sitting
Backend — new endpoint
Create:POST /cats/{cat_id}/insightsReturn a structured JSON object with:
headline, summary, confidence
flags, suggested_actions
citations (entry id + excerpt)
Retrieval (start simple)
Fetch the newest 5–10 sightings assigned to the cat
Build a context bundle string from them
Caching
Store results in SQLite
Cache key:
(cat_id, mode, prompt_version, context_hash)On cache hit → return stored insight JSON
Frontend
Show “Get cat profile (AI)” when
cat_idexistsCall the endpoint
Render the insight panel below the sighting
Testing
Test: no sightings → helpful error
Test: second call → cache hit, same schema
If you complete all five steps, you’ve built a real GenAI feature foundation.
10) Additional help / debugging notes
Blank frontend page
Check DevTools Console
Invalid hook call→ hook outside component or inside nested function
Nothing loads in Codespaces
Verify
.envcontains:VITE_API_BASE=https://<your>-8000.app.github.devEnsure ports 8000 and 5173 are set to Public
TypeScript errors
Update frontend types to match backend JSON exactly
Treat the backend response schema as the source of truth
About this series
I’m shipping 40 small AI projects in 40 weeks to rebuild hands-on AI engineering skills.
Each project:
ships in ≤3 hours
focuses on one real feature
starts with explainable logic before models